

Вы наверняка задавались вопросом, как работают SPY-сервисы под Facebook. Некоторые могут даже подумать, что владельцы спаев заключили тайный договор с Цукером и рептилоидами. И поэтому грузят крео пачками и без ограничений.
Но все гораздо проще! Есть такой инструмент – Facebook Ad Library API. А мы расскажем, что это и как работает.
Что такое Facebook Ad Library API
Как можно догадаться, это открытый API рекламной библиотеки Фейсбук. Он дает бесплатный доступ к базе крео Facebook и Instagram. Но чтобы им пользоваться, нужно хоть немного разбираться в программировании. В документации написано, что работа с API позволяет извлекать данные о рекламных кампаниях и фильтровать их по дате, языку, ГЕО, ключевым словам и другим критериям.
Один из плюсов Facebook Ad Library – объявления, нарушающие правила платформы, не удаляются из архива. Таким образом, через API можно получить доступ ко всем крео, что были размещены на платформе с 2018 года.
Именно благодаря фильтрам API разрабы и создают инструменты для отслеживания рекламных объявлений – SPY-сервисы. А вы ими успешно пользуетесь.
Структура объявления Facebook Ad Library
Для работы с Facebook API и удаленных запросов, в первую очередь, нужно понять структуру объявления. На скрине мы отметили элементы, из которых состоит креатив.
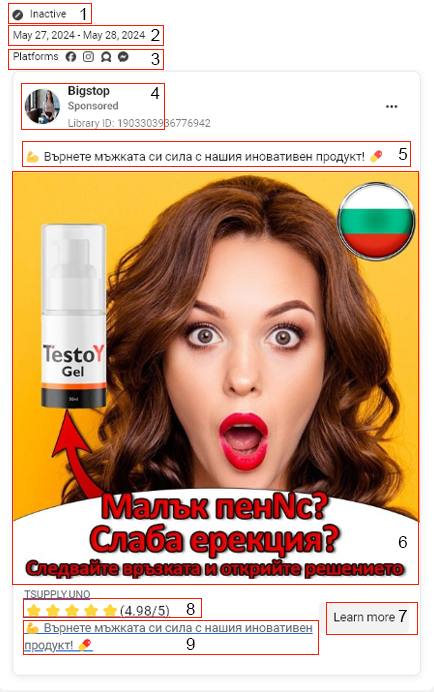
- Active/Inactive status;
- Start Date: ad_delivery_start_time;
- Disclaimer/Funding: funding_entity;
- The page running ad: page_name;
- Ad creative body: ad_creative_body;
- Image/Video ;
- Link & “Call to action”;
- Link caption: ad_creative_link_caption;
- Link description: ad_creative_link_description.
На самом деле данных из API можно получить гораздо больше, включая аудиторию и интересы. Но об этом поговорим чуть позже.
Условия для доступа к API
Есть несколько условий, чтобы получить доступ к API библиотеки рекламы Фейсбук:
- Первое: необходимо подтвердить аккаунт и местоположение, что может занять до 48 часов;
- Второе: перейти в Facebook Developers и создать там учетную запись;
- Третье: создать приложение Facebook для использования API.
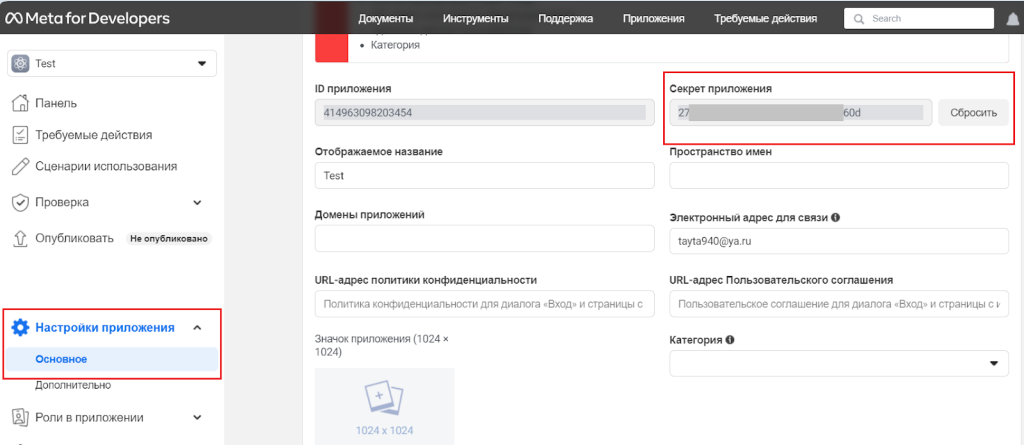
Обратите внимание на идентификатор приложения (App ID) и секретный ключ приложения (App Secret), которые можно найти в разделе Настройки/Основное (Settings/Basic) вашего приложения.
Как пишут в некоторых источниках по настройке API, Facebook не дает «постоянный» токен доступа. После входа в систему вы получаете краткосрочный (максимум 2 часа) токен. Его можно получить из Graph API Explorer.
Для того, чтоб обойти этот порог и продлить срок действия токена до двух месяцев, перейдите в инструмент Access Token Debugger, вставьте токен, нажмите Debug. А затем – кнопку Extend Access Token под информационной панелью. В появившееся поле введите пароль от Facebook
Этапы, из которых состоит API-запрос
Это – инфа для тех, кто немного понимает в техничке и программировании. Так производится API-запрос, чтобы получить нужную инфу из библиотеки.
Загрузка необходимых пакетов
Знать это необязательно, но для общего развития все-таки стоит прочитать. Вот из каких пакетов данных состоит формирование вашего запроса:
- httr – обеспечивает совершение API-запроса;
- remotes (потенциально) – может быть использован для установки пакетов;
- dplyr – для манипулирования данными;
- ggplot2 – для визуализации данных;
- tidyr – для очистки данных.
Настройка API-запроса
Для начала мы определяем URL-адрес конечной точки для архива объявлений в Graph API (версия 12.0).
Параметры запроса: Создаем список (my_query), содержащий критерии поиска, соответствующие примеру в официальной документации:
- search_terms – ключевые слова для поиска (например, “california”);
- ad_type – укажите тип объявления (например, “Helthy”);
- ad_reached_countries – целевые страны (например, “BG”);
- access_token – токен доступа к Facebook (хранится безопасно с помощью Sys.getenv(“FB_TOKEN”)).
Совершение API-запроса: Используем функцию GET пакета httr для отправки запроса с определенными URL-адресами и параметрами запроса. Дополнительно указывается заголовок для запроса JSON-ответа.
Обработка ответа
Она состоит тоже из нескольких этапов:
- Проверка статуса – проверяем код состояния ответа (идеально, если выдает 200 – для успешного завершения);
- Анализ ответа – извлекаем часть данных JSON-ответа с помощью httr::content(raw_response, as = “parsed”)[[“data”]]. Это приводит к вложенной структуре списка;
- Просмотр данных – получаем доступ к первому элементу в списке данных, чтобы увидеть содержимое первого полученного объявления.
Три параметра запроса выдачи объявлений
На скрине – пример выдачи через API Ad Library Фейсбук. Давайте разбираться, что интересного и полезного можно вытянуть из этой китайской грамоты.

Все это можно свести к трем большим параметрам, которые, в свою очередь, делятся на более мелкие показатели. Спойлер: информации здесь содержится просто море.
Ad content
Ad content – это все данные о самом креативе, включая тайминг открутки и целевой URL. Параметр включает следующие показатели:
- ad_creation_time – дата и время создания объявления;
- ad_creative_body – текст, сопровождающий рекламу;
- ad_creative_link_caption string – строка с URL, сопровождающая объявление. Присутствует необязательно. В примере крео, который находится выше, отмечена как 8;
- ad_creative_link_description – строка с текстом описания для ссылки, если таковой имеется. На скрине отмечена цифрой 9;
- ad_creative_link_title – строка с названием ссылки, если она имеется. На скрине отмечена цифрой 7;
- ad_delivery_start_time – дата и время начала показа объявления. Отображается в том же формате, что и ad_creation_time;
- ad_delivery_stop_time – время, когда покупатель хочет остановить кампанию. Это поле можно оставить пустым, тогда объявление будет работать до тех пор, пока его не остановят или пока не закончится бюджет. В том же формате, что и ad_creation_time;
- ad_snapshot_url – строка с URL-ссылкой на рендерер объявлений, который показывает снимок объявления с изображениями и видео без сжатия. Этот снимок сохраняется Facebook. Хотя сейчас функция массовой загрузки отсутствует, пользователи могут загружать отдельные креативы.
Ad Performance
Каждое из этих полей отражает реализованный результат рекламы – например, сколько показов было получено на самом деле (в пределах диапазона). Информация о таргетинге, – как его настраивал рекламодатель, – недоступна. Сюда входят только фактические данные по охвату и аудитории крео:
- demographic_distribution – демографическое распределение аудитории, которую охватило объявление. Это возвращает в объекте JSON (см. раздел «Как запрашивать» ниже) список кортежей. Каждый кортеж состоит из (возрастной диапазон, пол, процент). Для каждой комбинации «возрастной диапазон» x «пол» отображается процент показов в этой группе.
Варианты возрастных диапазонов: 18-24, 25-34, 35-44, 45-54, 55-64, 65+;
Пол – «Мужской», «Женский», «Неизвестный» (неизвестный означает, что пол не известен Facebook);
- region_distribution – распределение аудитории по регионам, на которые попало объявление. Кортежи (регион, процент), в том же формате, что и демографическая информация. Регионы – это уровень провинции/штата, в зависимости от страны;
- spend – показывает примерную общую сумму, в которую обошлась реклама. В единицах валюты. Это сообщается в диапазонах: <100, 100-499, 500-999, 1K-5K, 5K-10K, 10K-50K, 50K-100K, 100K-200K, 200K-500K, >1M;
- currency – показывает валюту, которая была использована реклом для оплаты объявления;
- impressions – количество показов объявления на экране. Это число указывается в диапазонах <1000, 1K-5K, 5K-10K, 10K-50K, 50K-100K, 100K-200K, 200K-500K, >1M.
Ad Purchaser Information
А это – инфа о рекламодателе, странице, от имени которой разместили объявление. Здесь всего три значения:
- funding_entity – имя физического или юридического лица, финансирующего объявление, представленное покупателем объявления. Проще говоря – имя рекла;
- page_id – идентификатор страницы Facebook, на которой было размещено объявление. Чтобы перейти на страницу с соответствующим идентификатором страницы, пользователь может ввести идентификатор страницы в поле www.facebook.com/[page_id];
- page_name – название страницы на момент запуска крео. Все следующие смены названия не показываются.
Вся инфа о реклах и фан пейдж актуальна на момент запуска объявления. Если затем владелец акка переименовал страницу, сменил пол, страну и валюту, это не будет отображаться.
Что будет полезно изучить?
Как видите, большинство запросов соответствует фильтрам SPY-сервисов. И, если вы умеете пользоваться API библиотеки рекламы, то по сути получаете доступ к бесплатному спаю. Причем с подробнейшими данными о каждом объявлении, которое крутилось в более чем ста ГЕО. Или, как вариант, можете организовать собственный спай.
А вот список полезных ссылок, которые вам в этом помогут:
- Открытый репозиторий GitHub – https://github.com/facebookresearch/Ad-Library-API-Script-Repository
- Chapter 5 Facebook Ad Library API | APIs for social scientists: A collaborative review: https://bookdown.org/paul/apis_for_social_scientists/facebook-ad-library-api.html
- Ad Library API Codebook: https://socialscience.one/files/ad_library_api_codebook.pdf
Заключение
Заговор масонов, Цукерберга и владельцев спаев мы только что отменили. Зато дали вам в руки годный инструмент для выгрузки креативов из библиотеки рекламы FB. И, возможно, даже создать собственный spy-сервис и зарабатывать на этом.







